GPT4All簡介(二)
前文介紹了GPT4All 的下載、安裝、以及大型語言模型(LLM)的下載說明,本文將簡介GPT4All的基本操作方式、以及GPT4All本機端RAG的使用方式。
交談(Chat)
和OpenAI、Mistral、Gemini等生成式AI一樣,GPT4All也是以交談(chat)的形式和LLM互動,主要的差別是:一般的生成式AI是透過雲端系統提供服務,使用者必須透過網路登入或連接到GenAI系統才能使用;而GPT4All則安裝在使用者端的電腦中,由於所需要的LLM已經下載到使用者端的電腦,所以,即使沒有連接網路也能正常運作。
點選GPT4All軟體首頁的「開始交談」、或左方側邊欄的「交談」:
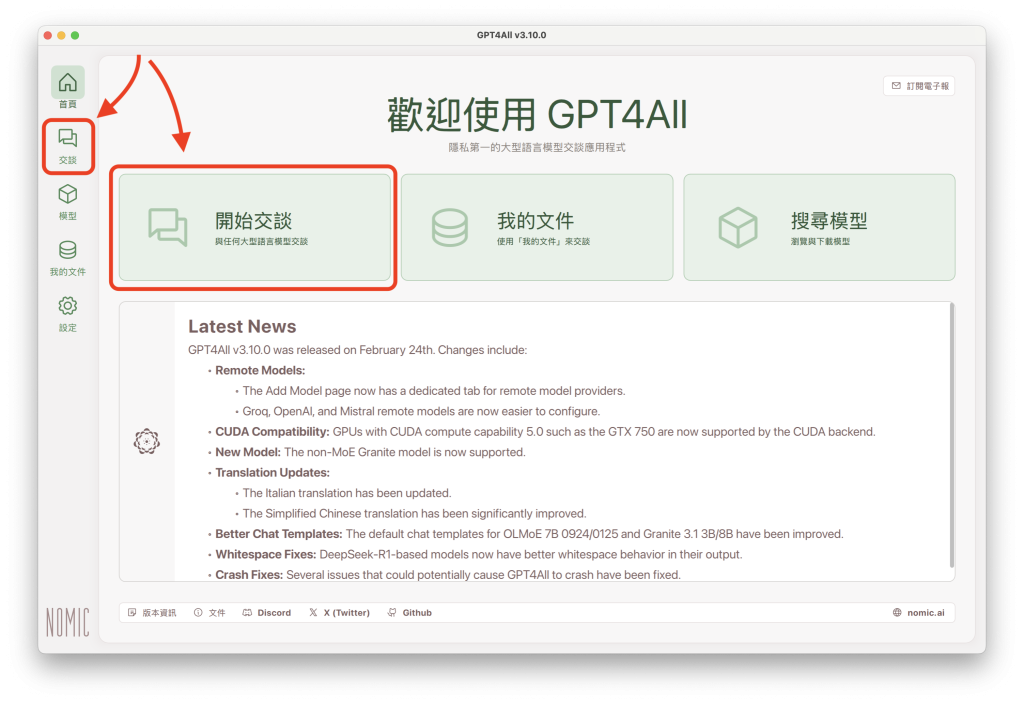
會開啟一個新的交談(New Chat):
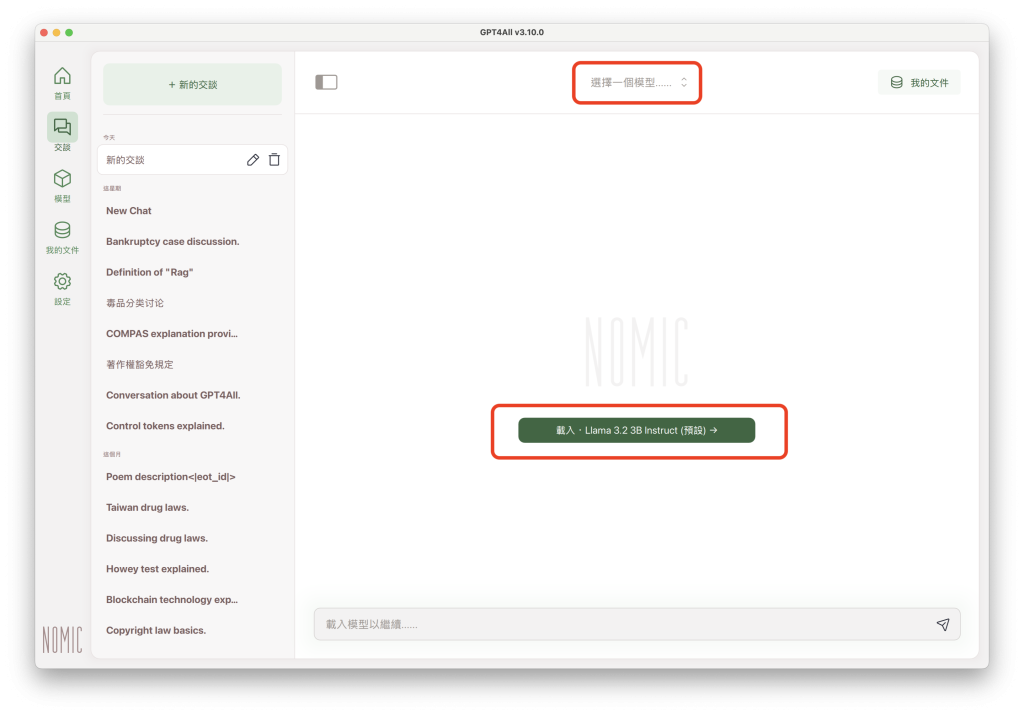
點擊中央的綠色按鈕,會載入之前已下載的LLM。這裡所謂的「載入」(load),是指匯入本次交談所要使用的LLM。因為GPT4All可以下載二個以上的LLM(但要注意硬碟空間是否足夠),每次交談時都可以從已下載的LLM選單中,選擇本次交談所要使用的LLM。
如果只下載一個LLM,中央綠色按鈕所標示的LLM,就是預設使用的LLM。
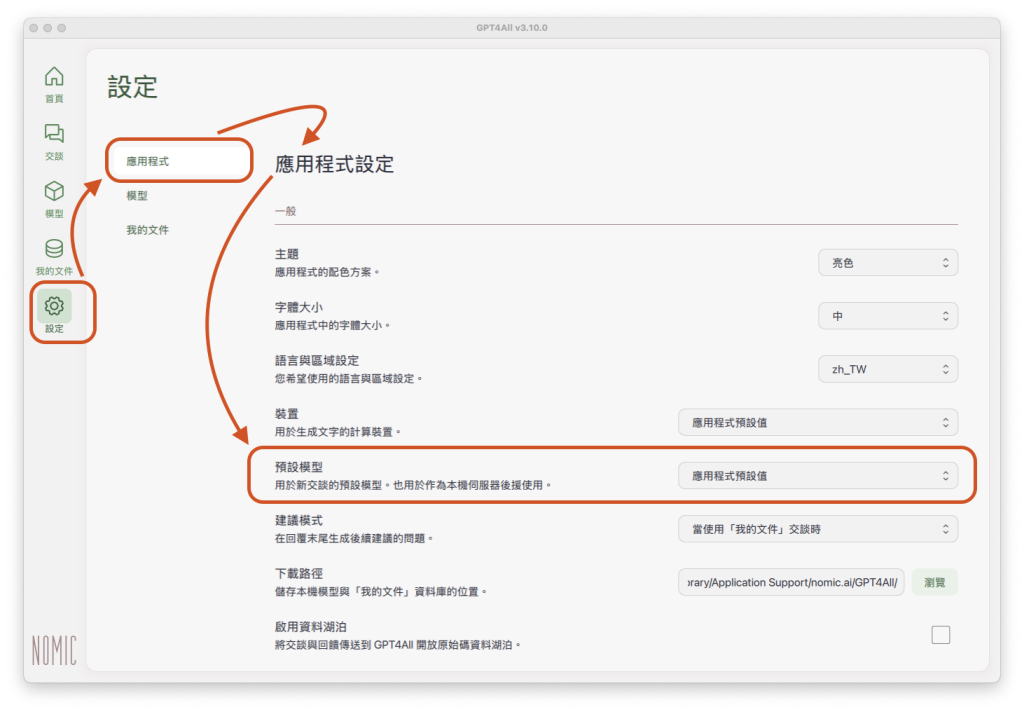
如果之前已經下載過二個以上的LLM,可以在左方側邊欄「設定」>「應用程式」>「預設模型」中,設定將來交談時預設使用的LLM:
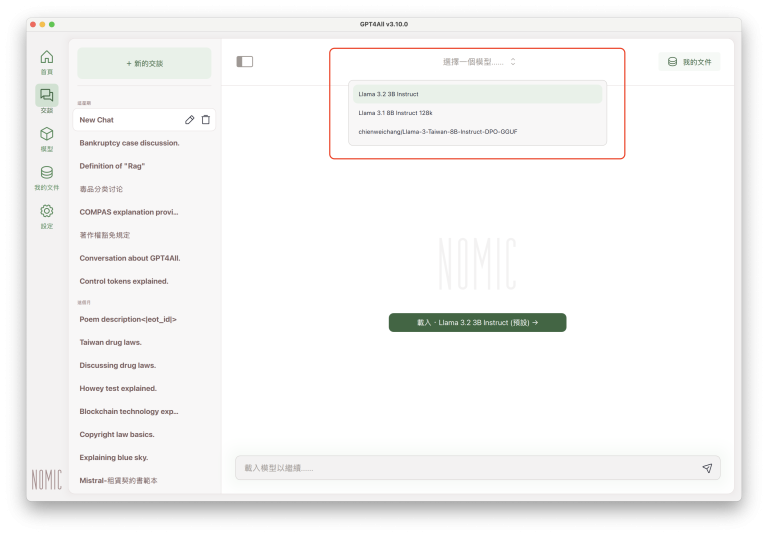
每次開啟交談時,如果不想使用預設的LLM,可以點一下畫面上方的「選擇一個模型……」,就會出現已下載的LLM選單,可以從選單中選擇要載入的大型語言模型(只是從已經下載的LLM中選擇,不會重新下載):
大型語言模型載入完成後,就可以開始提問、開始和本機電腦的聊天機器人(chatbot)互動:
即使是在交談進行中,只要點選左上方的「+新的交談」:
就可以隨時開啟一個新的交談:
GPT4All交談的使用方式,和ChatGPT、Gemini的使用方式一樣,採問答的方式進行:
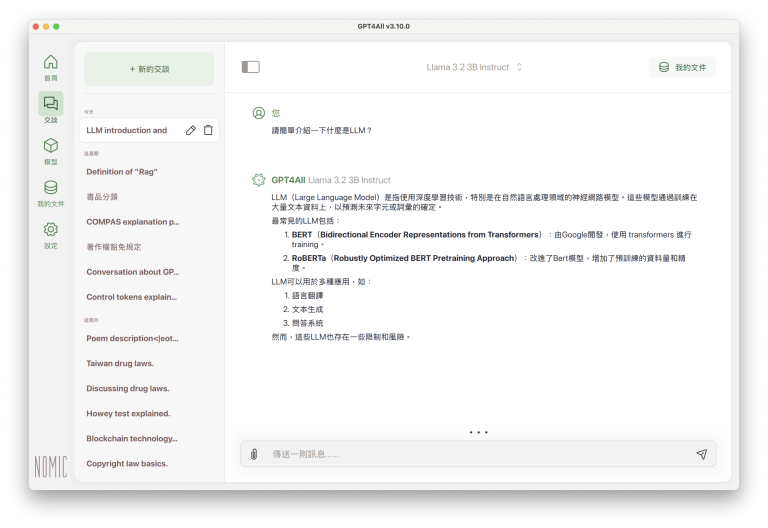
交談視窗的左方,是之前交談的歷史紀錄(下圖藍框),點選任何一筆歷史紀錄(下圖紅框),就可以看到當時交談的提問、以及LLM的答覆內容:
點選任何一筆交談紀錄後,該筆交談紀錄名稱的右方,會出現二個圖示:鉛筆和垃圾桶:
點選鉛筆圖示,可以修改交談紀錄的名稱;點選垃圾桶圖示,可以刪除該筆交談紀錄(修改名稱或點選刪除圖示後,按「✓」圖示,表示確認修改或刪除)。
如果將滑鼠移標移動到LLM的答覆內容,LLM答覆的最後一行左下方,會出現二個圖示:
點選第一個圖示「Redo」,可以針對同一個提問,請LLM重新答覆,不必再重新輸入相同的提問;這個功能可以使用在第一次提問、LLM也完成答覆之後,匯入文件、請LLM根據文件再答覆一次的時候;這項功能可以檢測匯入參考文件之前、匯入參考文件之後,LLM答覆內容的差異(詳後述),藉此瞭解LLM解讀文件的能力、以及提問方式和內容對LLM答覆內容的影響。
點選第二個圖示「複製(copy)」,可以將LLM的答覆內容複製到作業系統的剪貼簿,就可以貼到其他應用程式(例如Microsoft Word),作為工作底稿或素材。
本機端RAG
建立參考資料夾
RAG的基本概念是:在LLM的基礎上,加上額外提供的資料或文件,讓LLM在生成回覆內容時,可以參考額外提供的資料或文件,生成”有所本”(grounded)的回覆內容,使LLM可以配合特定知識領域的特殊性或時效性,做成更精準、更確實的答覆,並降低AI幻覺(hallucination)的風險。
GPT4All的RAG功能,就是簡化成匯入額外資料或文件。額外提供的資料或文件,是匯入「我的文件」(LocalDocs)。
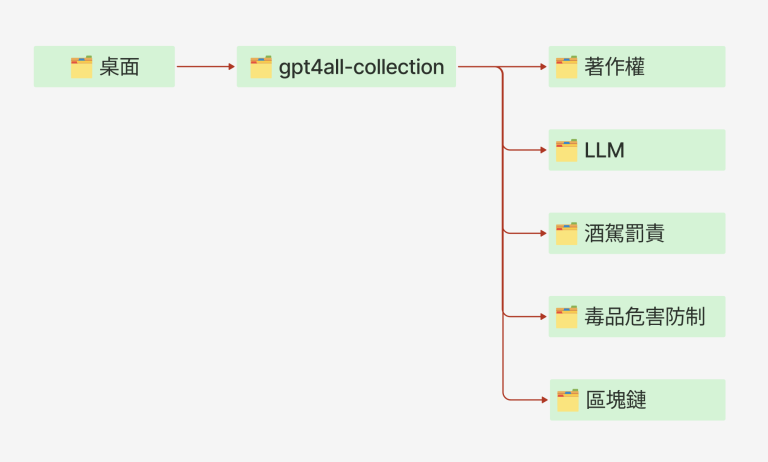
剛開始,建議先在電腦桌面上建立一個資料夾,例如「gpt4all-collection」,接著,在這個資料夾裡為每個有興趣的主題、或同一個主題但不同資料型態,再建立一個獨立的資料夾,例如著作權、LLM、酒駕罰則、毒品危害防制、區塊鏈等,完成後,桌面上「gpt4all-collection」的資料夾結構會類似下圖:
接著把希望匯入GPT4All的資料檔案或文件檔案,依照不同主題、或不同資料型態,分別複製一份、存入各該主題資料夾。
以資料夾區分不同主題、或不同資料型態,一方面可以方便管理和使用不同的領域研究,另一方面也可以從各種不同領域或資料型態,檢測所使用的LLM,在參照所匯入的領域知識或資料型態後,是不是有所差異?是不是更精確、更可靠?能不能達到預期目的?之後就可以逐步調整,例如使用不同的LLM、變換不同的參考資料或文件等等。
對GPT4All的使用和設定方式較為熟悉之後,就可以將參考資料夾移到平常工作習慣的路徑,不必再重複複製。
將資料夾加入「我的文件」
在GPT4All軟體首頁,點選正中央的「我的文件」(LocalDocs)、或左方側邊欄的「我的文件」:
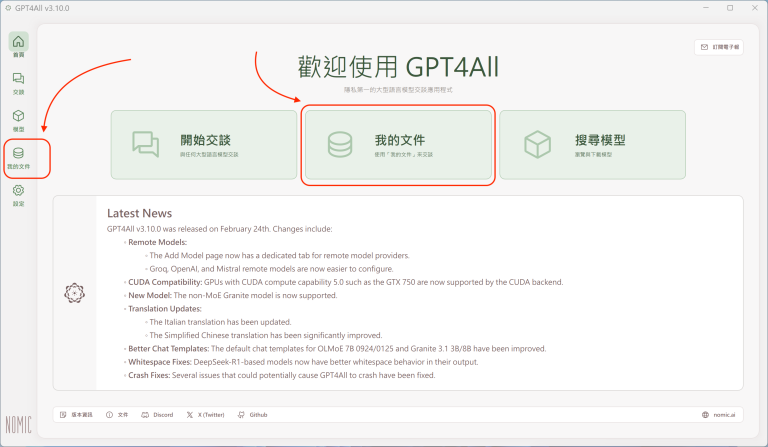
都可以進入「我的文件」管理畫面:
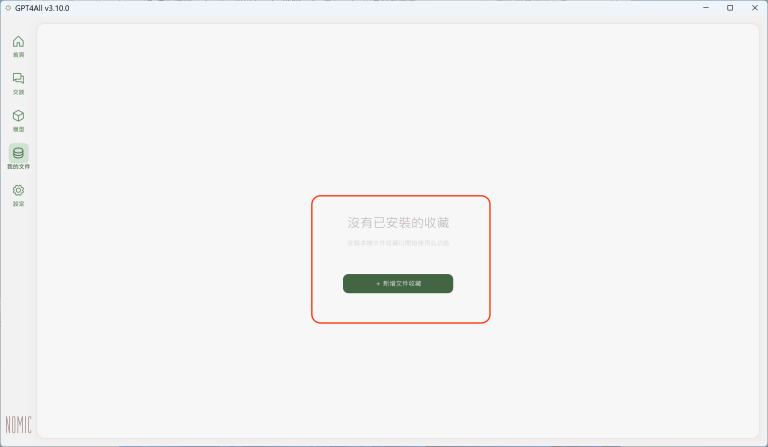
若之前沒有匯入過資料或文件,會顯示「沒有已安裝的收藏」。只要點選「+新增文件收藏」,就可以開啟「新增文件收藏」設定頁面:
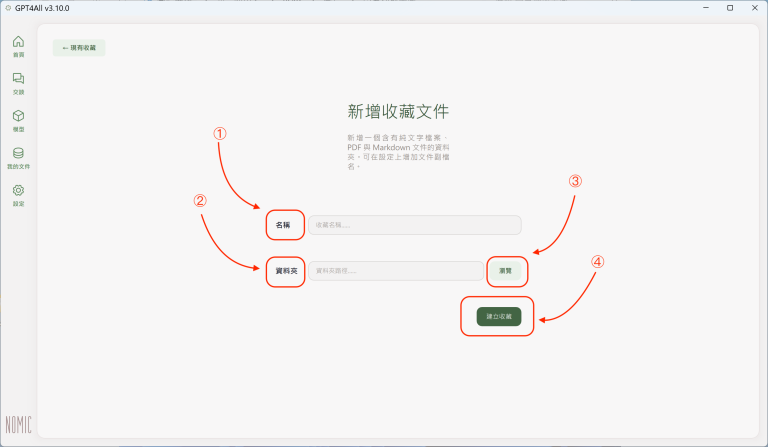
(1) 在「名稱」欄位中填入資料或文件的名稱;可以填入之前所建立的各個主題資料夾的資料夾名稱,以便於辨識與管理。
(2) 點選在「資料夾」欄位右方的「瀏覽」按鈕,可以開啟作業系統的資料夾選擇畫面(以Windows系統為例):
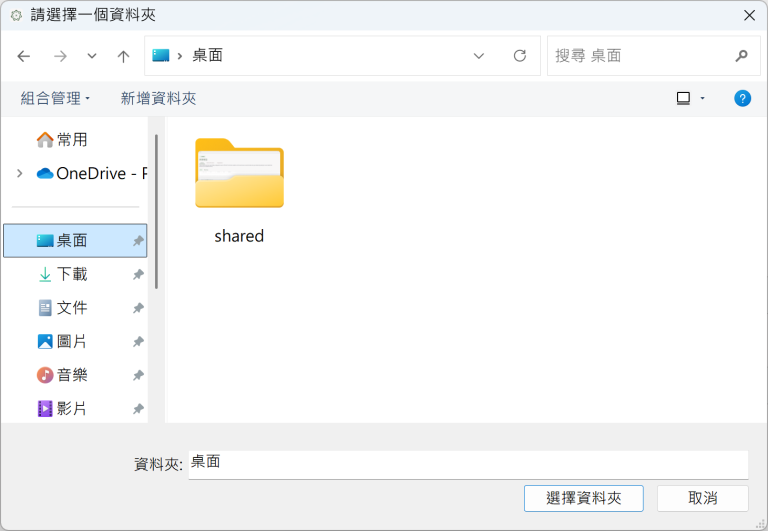
(3)選定資料夾之後,會回到「新增文件收藏」設定頁面,按「建立收藏」按鈕:
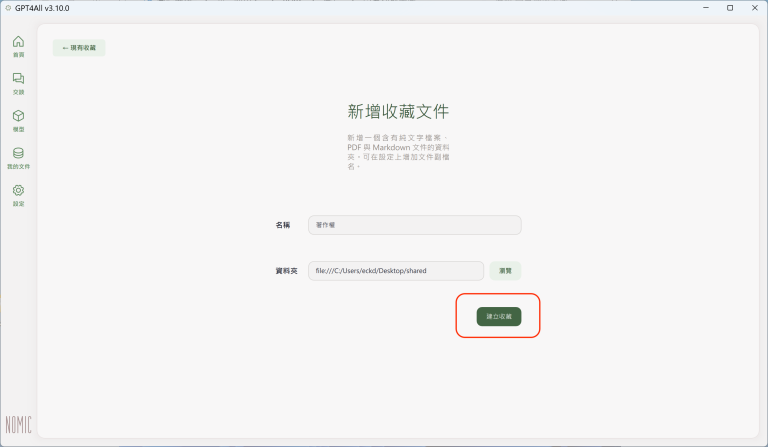
(4) 這樣就完成一個資料夾的設定。所選定的資料夾會出現在「我的文件」清單中:
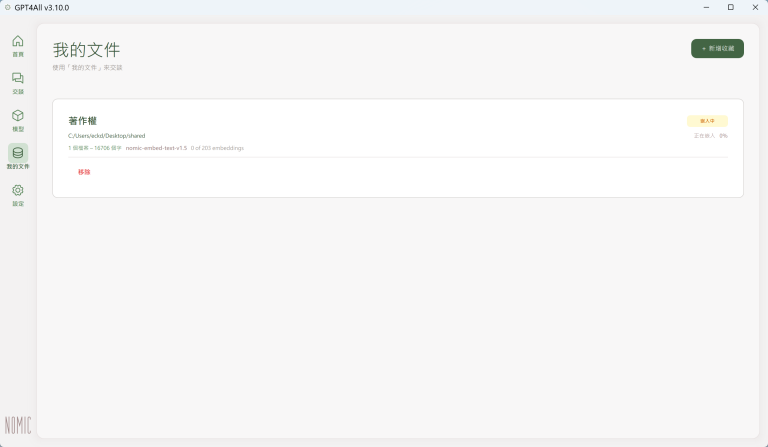
其他資料夾也依照上述流程逐一加入之後,「我的文件」會顯示所有已加入的資料夾、每個資料夾裡的檔案數:
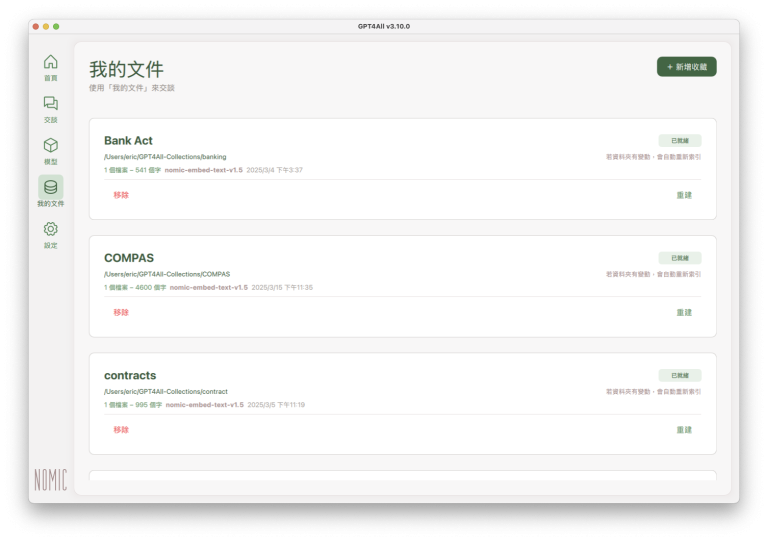
加入參考資料
進入交談模式後,開始提問之前、或交談進行中,都可以按一下視窗右上方「我的文件」:
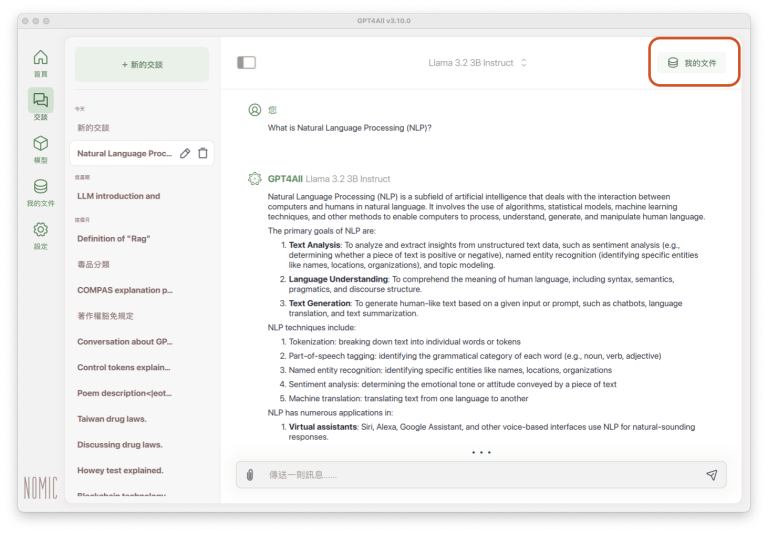
下方就會開啟剛剛建立的參考資料夾清單:
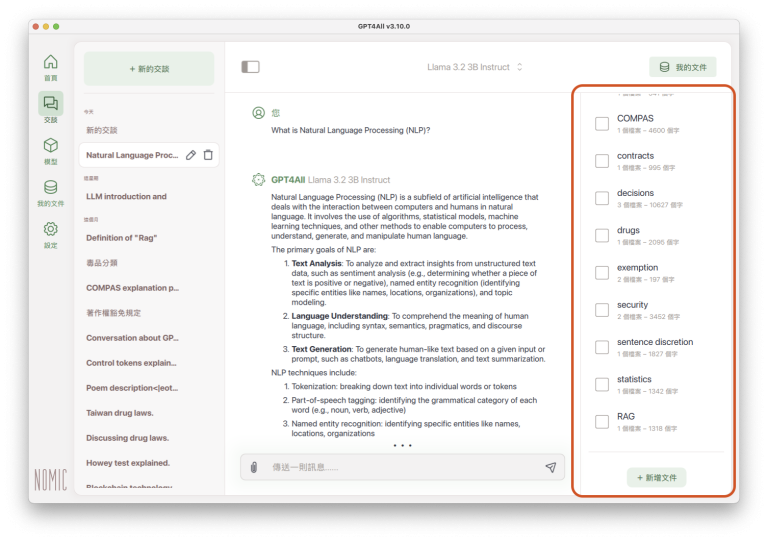
點選資料或文件所在的資料夾方塊,原本空白的方塊變成綠色時,就表示已指定參考文件,接著就可以要求LLM依照所指定的參考資料或文件答覆:
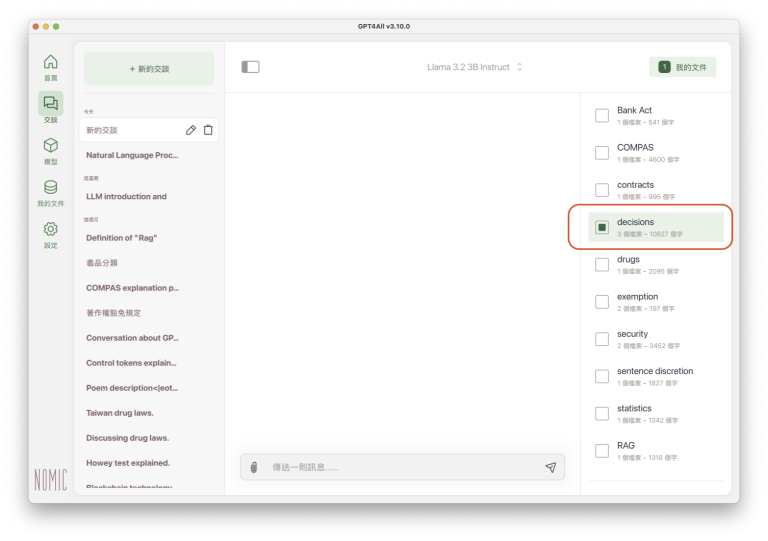
實例
以下用一個簡單的例子,說明匯入參考文件之前、之後,LLM答覆內容的差異。
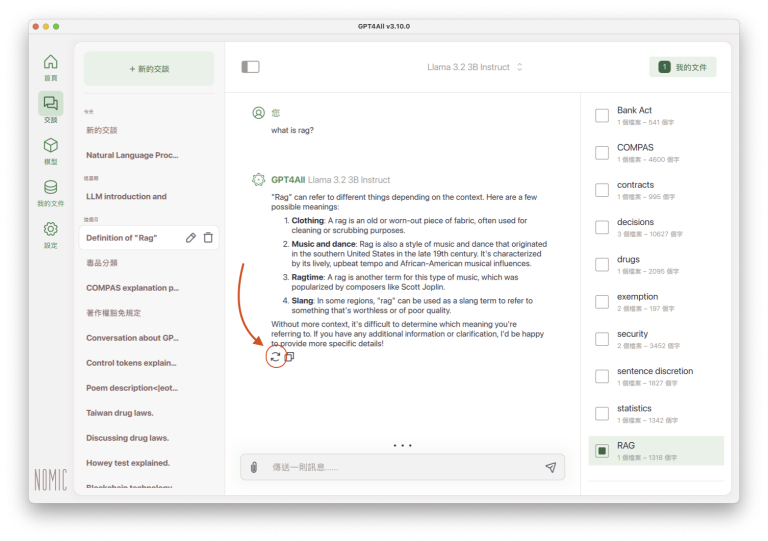
匯入文件之前,提問一個簡單的問題:「what is rag?」(什麼是rag?)。LLM的答覆如下圖(留意視窗右方「我的文件」,沒有選定任何參考資料):
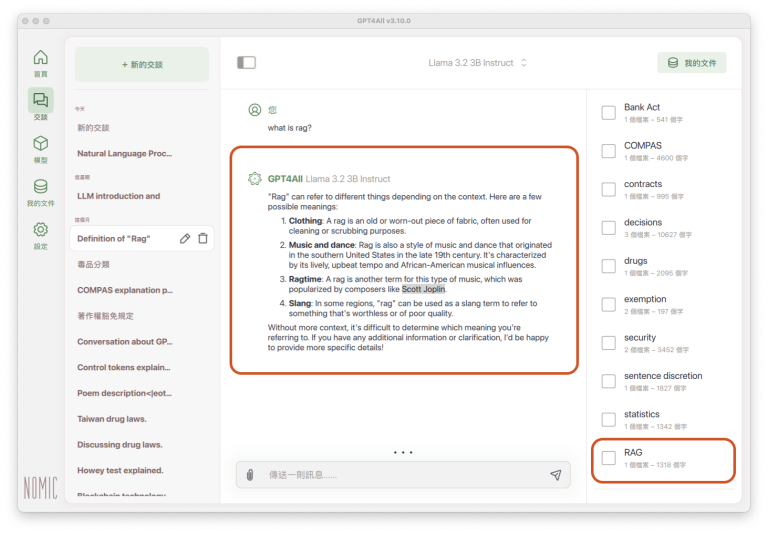
LLM的答覆內容大約是:依照前後文義(context),“Rag” 可以有不同的意義,例如「衣物」(破舊的衣物)、「音樂舞蹈」(一種音樂舞蹈的風格)、「音樂」(Ragtime,由Scott Joplin所帶動的音樂風格)、「罵人的粗話」(胡鬧)。這相當於一般字典上的解釋、再加上一點維基百科的風格(關於Ragtime的說明)。
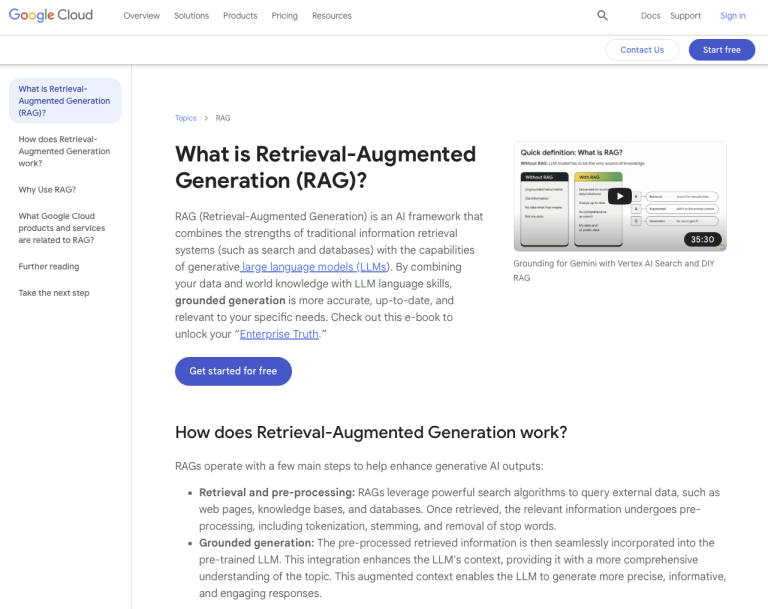
但我們真正想問的,其實是RAG (Retrieval-Augmented Generation)。所以,筆者在Google上用”RAG”搜尋,找到Google Cloud一篇關於RAG的說明(What is Retrieval-Augmented Generation (RAG)?),並將該網頁轉為PDF檔、匯入交談當作參考資料(留意右下方,已指定「RAG」資料夾):
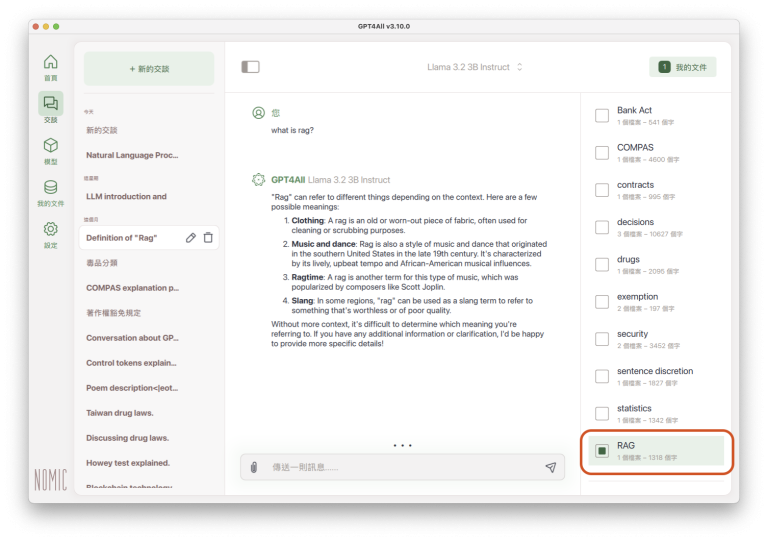
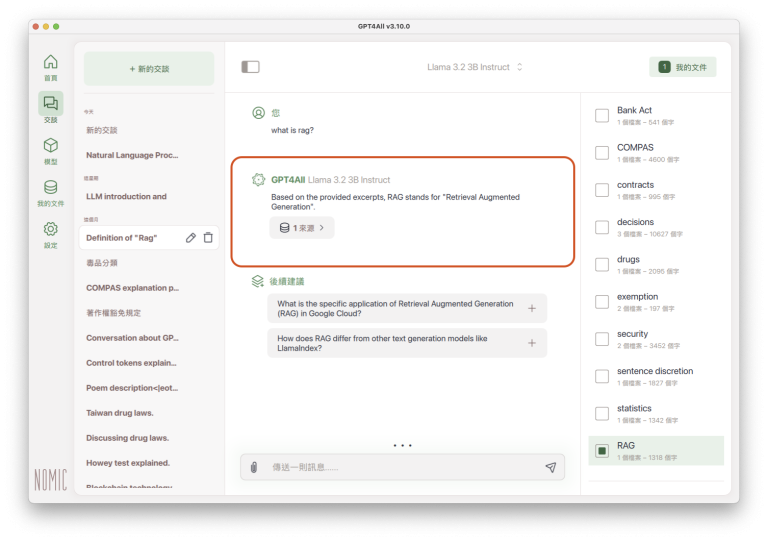
指定參考資料之後,點選LLM答覆內容最後一行下方的「Redo」(重新答覆)功能,要求LLM針對同一個問題,再答覆一次:
多了匯入的文件之後,LLM更清楚提問的真正含義,答覆內容也就更精確:根據所提供的文件,RAG是「Retrieval Augmented Generation」的縮寫:
當然,相較於Google Cloud的說明(如下圖),LLM的答覆內容實在太過簡略。
但這個例示只是為了顯示加入參考資料前後的差異,而且提問(what is rag?)非常簡略、又剛好和Google Cloud那一篇文章標題(What is Retrieval-Augmented Generation (RAG)?)幾乎完全相同,所以LLM只答覆「RAG 是“Retrieval Augmented Generation”的縮寫」。如果加入完整的資料或文件、或提問內容更有結構,應該會相當不同。
限於篇幅,關於GPT4All的相關參數設定,留待下一篇介紹。