本機端RAG簡介
RAG (Retrieval-Augmented Generation,擷取擴增生成),是針對 LLM (大型語言模型)在某些情況下的不足所設計的 GenAI (generative AI)架構,本文將從目前 GenAI 的概況談起,簡要介紹 RAG 和本機端 RAG 的概念和基本架構。
AI 浪潮
自從 ChatGPT 在2022年底公開上線以來,生成式 AI (Generative AI, GenAI)、大型語言模型 (Large Language Model, LLM)、自然語言處理(Natural Language Processing, NLP)技術和應用就以驚人的速度成長,不只是 OpenAI 的 ChatGPT 在上線後5天內吸引超過100萬名使用者、二個月後達到1億名使用者,其他聊天機器人(chatbot)如 Claude (Anthropic)、Copilot (Microsoft)、Perplexity、Gemini (Google)、Grok (xAI)、Mistral 也快速成長。不止如此,DALL.E (OpenAI)、Stable Diffusion (Stability AI)、Midjourney 等圖像生成 AI,也已經和聊天機器人一樣普及。
而且,自從 BLOOM (BigScience)、Llama (Meta)、Mistral 採用開放原始碼 (open source) 模式以來,各式各樣的 AI 應用更是以爆炸性的速度席捲全球。在知名的 Hugging Face 平台上發布的各種模型 (models) 已經超過150萬個,AI 應用也深入 GitHub、Notion、Grammarly 和 Canva 等服務,連老牌的 Adobe 也不能免俗。用 AI 寫程式也不再是聳動的新聞,早在2023年就出現一種不完全是開玩笑的說法:現在最熱門的程式語言是英文。
LLM / RAG
在一般應用上,ChatGPT、Perplexity、Claude、Gemini 等大型語言模型已經令人驚艷,但在某些情況下,尤其是和時間及領域知識(domain knowledge)有關的時候,可能就難以配合使用者的特定需求。例如:ChatGPT 是不是有能力提供某特定公司的即時資訊?用一個在 ChatGPT 上所做的簡單測試來說明:
先詢問 ChatGPT:是不是可以根據特斯拉(Tesla) 的 2024 年報 (Form-10K),做一份特斯拉2024年營運表現摘要?特斯拉是世界知名公司,而且是在美國紐約證券交易所(NYSE)公開上市的公司,當然沒問題,而且 ChatGPT 還一併摘要特斯拉最近的紛紛擾擾。(參閱:ChatGPT原始對話副本連結)
知名公司沒問題,那麼,一般人不太熟悉的公司呢?再問一下 ChatGPT:是不是可以做一份 Wiz Inc. 2024年的營運表現摘要?這家公司不像特斯拉一樣家喻戶曉,但實際上並不是默默無名,最近才剛傳出 Alphabet (Google母公司) 以超過320億美元的估值併購 Wiz。所以,就算不是人盡皆知的公司,ChatGPT 也可以輕鬆應付。(參閱:ChatGPT原始對話副本)
如果是更不知名的公司呢?Wiz 是雲端系統資安公司,所以筆者在 Y Combinator 以 “cloud security” 搜尋,並從搜尋結果清單中隨機挑選一家公司(以下簡稱 “XXX 公司”),並詢問 ChatGPT:是不是可以做一份 XXX 公司2024年的營運表現摘要?以下是 ChatGPT 原始對話副本(已遮蔽公司名稱):

ChatGPT 的答覆是無法提供XXX公司的資訊,但可能是因為過意不去(?),所以 ChatGPT 還是努力提供了三則似乎和XXX公司名稱有關的產品資訊;不過,那三則訊息實際上都和XXX公司無關。可見,如果詢問內容是關於欠缺公開資訊的公司,ChatGPT 就難以提供協助。
當然,ChatGPT 有「附加」功能(上傳檔案)。如果是因為某些原因(例如公司查核)已經持有XXX公司的龐雜資料,希望藉由 GenAI 協助整理或製作摘要而使用「附加」功能,將XXX公司資料匯入 ChatGPT,ChatGPT 應該就可以分析上傳的資料,並根據上傳的資料生成回覆內容。
不過,涉及個人資料、隱私或營業秘密的資訊,應該不適合上傳到一般的雲端 AI 系統。從保護個資和維護機密資訊的角度來看,建置在本機端 (local devise) 的 RAG (Retrieval-Augmented Generation),就是非常適合的選項。
什麼是RAG
RAG 一般翻譯為「擷取擴增生成」(Retrieval-Augmented Generation),基本概念就是以大型語言模型為基礎,加上額外匯入的資料或文件,讓 GenAI 在答覆提問的時候,可以有更高的精準度和確實性,並降低 AI 幻想 (hallucination) 的風險,因為所附加的額外資料或文件,可以讓大型語言模型在生成答覆內容的時候有所依據。如果計劃將 GenAI 使用於特定知識領域(specific domains),例如法律、醫療、金融等領域,就可以考慮 RAG 架構。
參照 LangChain 對 RAG 的說明,RAG 架構可以分成 Indexing (建立索引)和 Retrieval & Generation (擷取及生成)二個部分:
建立索引
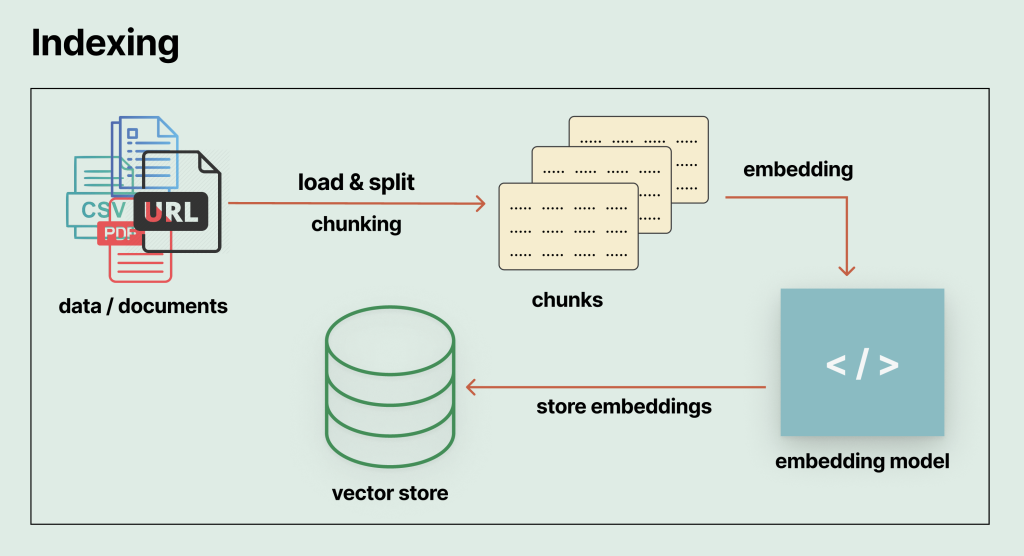
建立索引的階段,是將本機端匯入的資料或文件切分成片段(chunk),再將所有片段的字串轉換為電腦可以處理的數值(numerical representation),轉換後的數值稱為崁入向量(embedding vector),接著再將崁入向量存入向量資料庫(vector database),以備將來使用。建立索引階段的基本架構流程如下圖:
擷取及生成
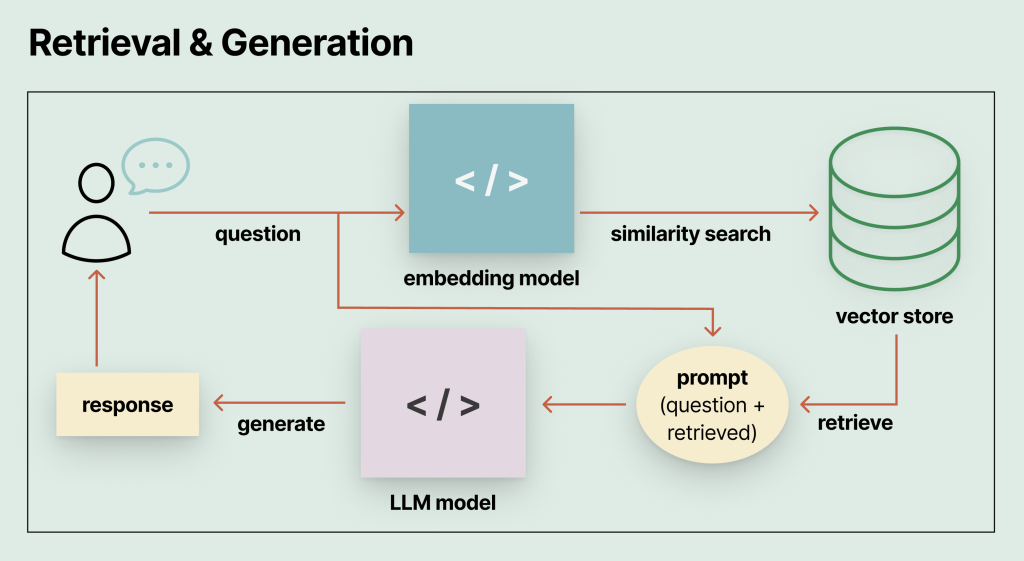
匯入資料、完成索引的階段完成之後,實際使用 RAG 提問時,系統會將提問內容再進行一次”分切成片段”、”轉換為崁入向量”的過程,再以轉換所得的結果,在向量資料庫中進行類似性搜尋(similarity search),並將搜尋所得的結果從資料庫中擷取出來,與提問內容一併結合成提示詞(prompt),送入系統所使用的大型語言模型中生成回覆內容。因為整個階段經過”擷取“預先匯入的資料、以”增強” AI 生成內容的依據、再由大型語言模型”生成”最後的回覆內容,所以稱為”擷取擴增生成”。擷取擴增生成階段的基本架構流程如下圖:
什麼是本機端RAG
由於大型語言模型動輒以數十億、甚至上百億個參數(parameters)進行運算,必須有高規格的電腦運算力(computational capacity)才能有效率地運作。但模型量化(model quantization)技術和 GGUF 格式的發展(關於 GGUF 的說明,可以參閱這篇文章),讓欠缺電腦運算力的中小型公司或組織、甚至個人,也可以在沒有高階伺服器和 GPU 等硬體設備的情況下,在一般電腦中建置 GenAI;本機端 RAG 就是安裝在自有電腦系統上的 RAG 。
不止如此,圖形化介面、不需要寫程式、可直接安裝在個人電腦的免費、開源應用程式也相繼出現,例如 GPT4All、AnythingLLM。這些終端使用者等級的應用程式,讓一般人也可以輕鬆建立自己的 RAG 系統,不論安裝或使用方式都和一般下載版套裝軟體沒有差別,沒有 GPU 的個人電腦也可以執行。
在自有電腦上執行 RAG 最大的優點是資訊不外流,因為不只是大型語言模型已經下載到自己的電腦裡執行(不需要透過API),所有匯入 RAG 的資料或文件,也都保留在自有電腦裡,即使不連接網路也可以正常運作。
GPT4All 應該是目前使用者介面最清楚、友善的下載版 GenAI 應用程式,支援 Windows、macOS、Linux (Ubuntu),也內建繁體中文介面,對 GenAI、RAG 有興趣的人,都可以下載安裝,以便於實際測試各種大型語言模型和 RAG 的簡化版建置流程和效能,除了有助於進一步瞭解 LLM 和 RAG 如何運作,也可以快速建立一套個人專屬 GenAI / RAG。